Method
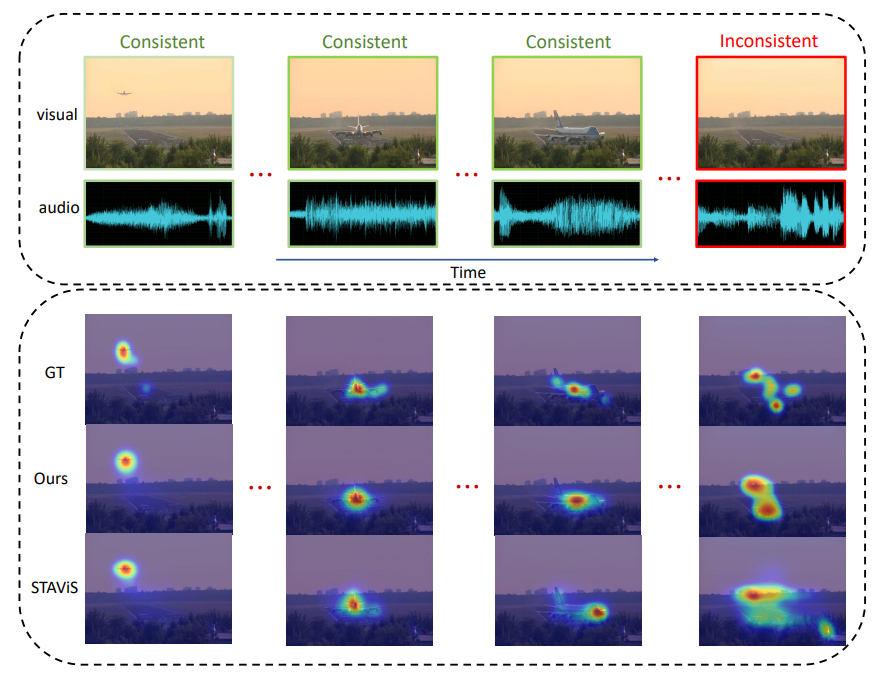
The example figure shows the saliency results of our model compared to STAViS in audio and video temporal
sequences. In the last time segment, the audio information that occurs in the event is inconsistent with the
visual information. Our method can cope with such challenge by automatically learning to align the audio-visual
features. The results of STAViS, however, show that it is incapable to address the problem of audio-visual
inconsistency. GT denotes ground truth.
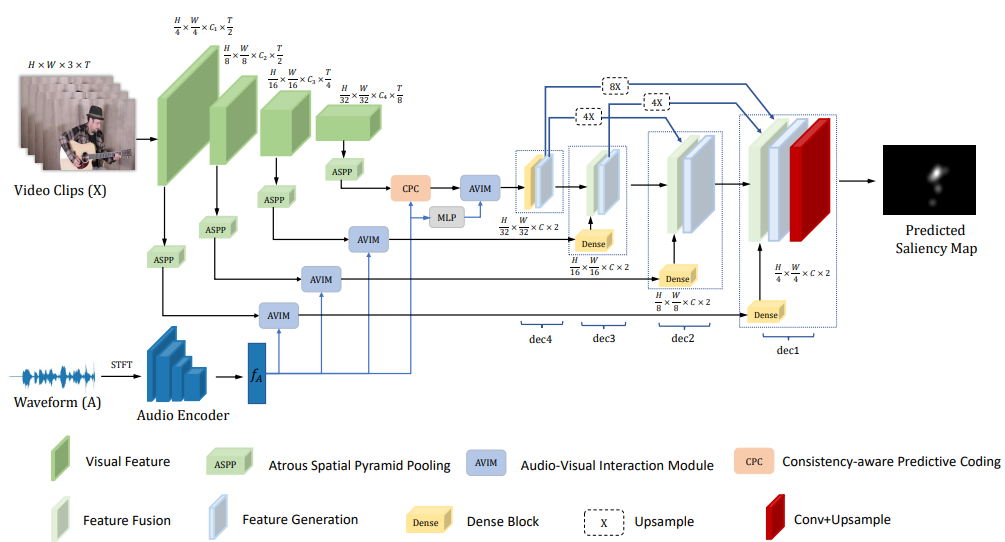
The proposed CASP-Net is composed of: a two-stream network to obtain visual
saliency and auditory saliency feature, an audio-visual interaction module to integrate the visual and auditory
conspicuity maps, a consistency-aware predictive coding module to reason the coherent spatio-temporal visual
feature with audio feature, and a saliency decoder to estimate saliency map with multi-scale audio-visual
features.