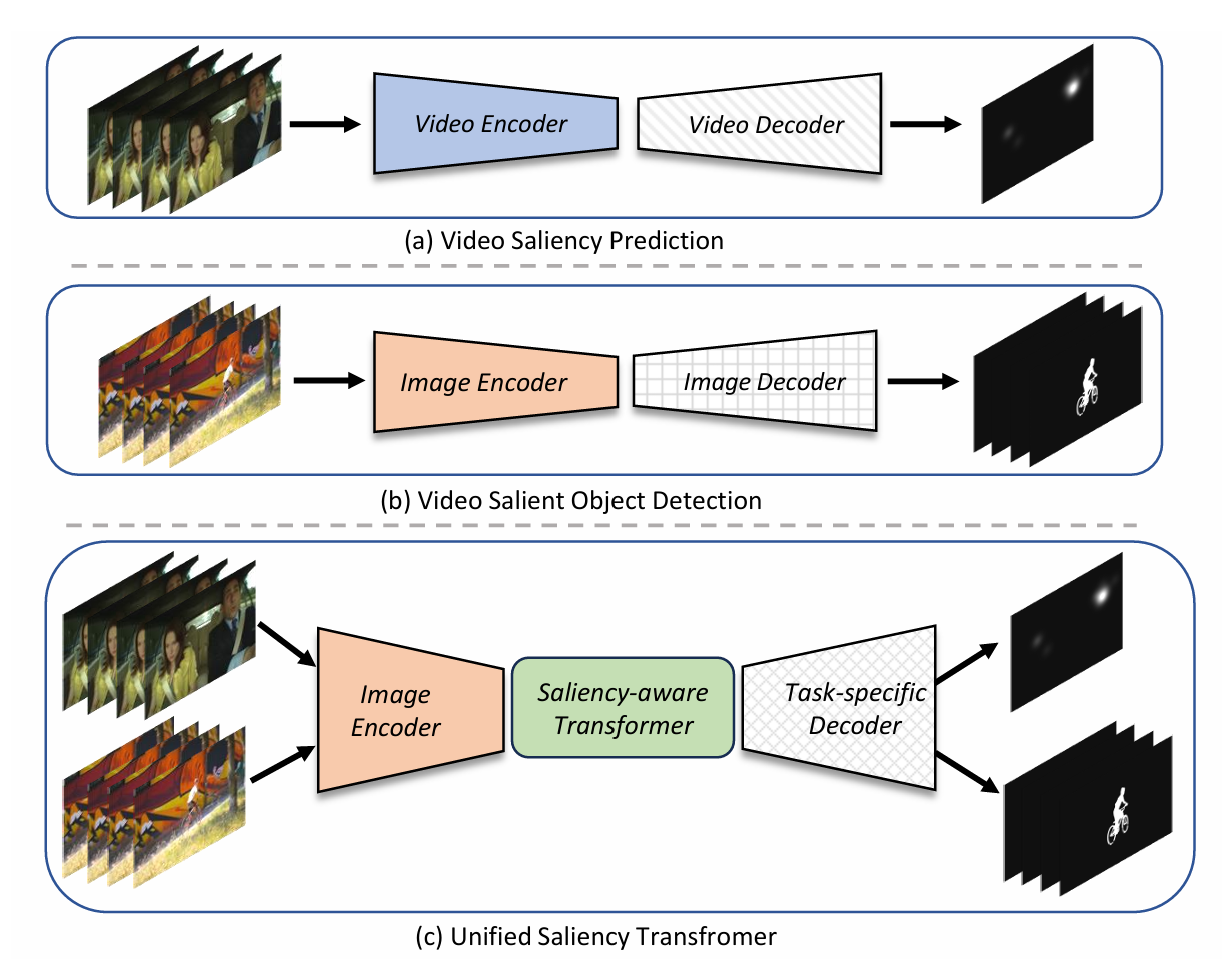
Method
The VSP and VSOD adopt video encoder and image encoder respectively as feature extractors, followed by corresponding decoders. Differently, a unified saliency transformer directly applies an image encoder for feature processing, and follows a transformer structure for spatio-temporal modeling, and finally uses different decoders for different tasks.
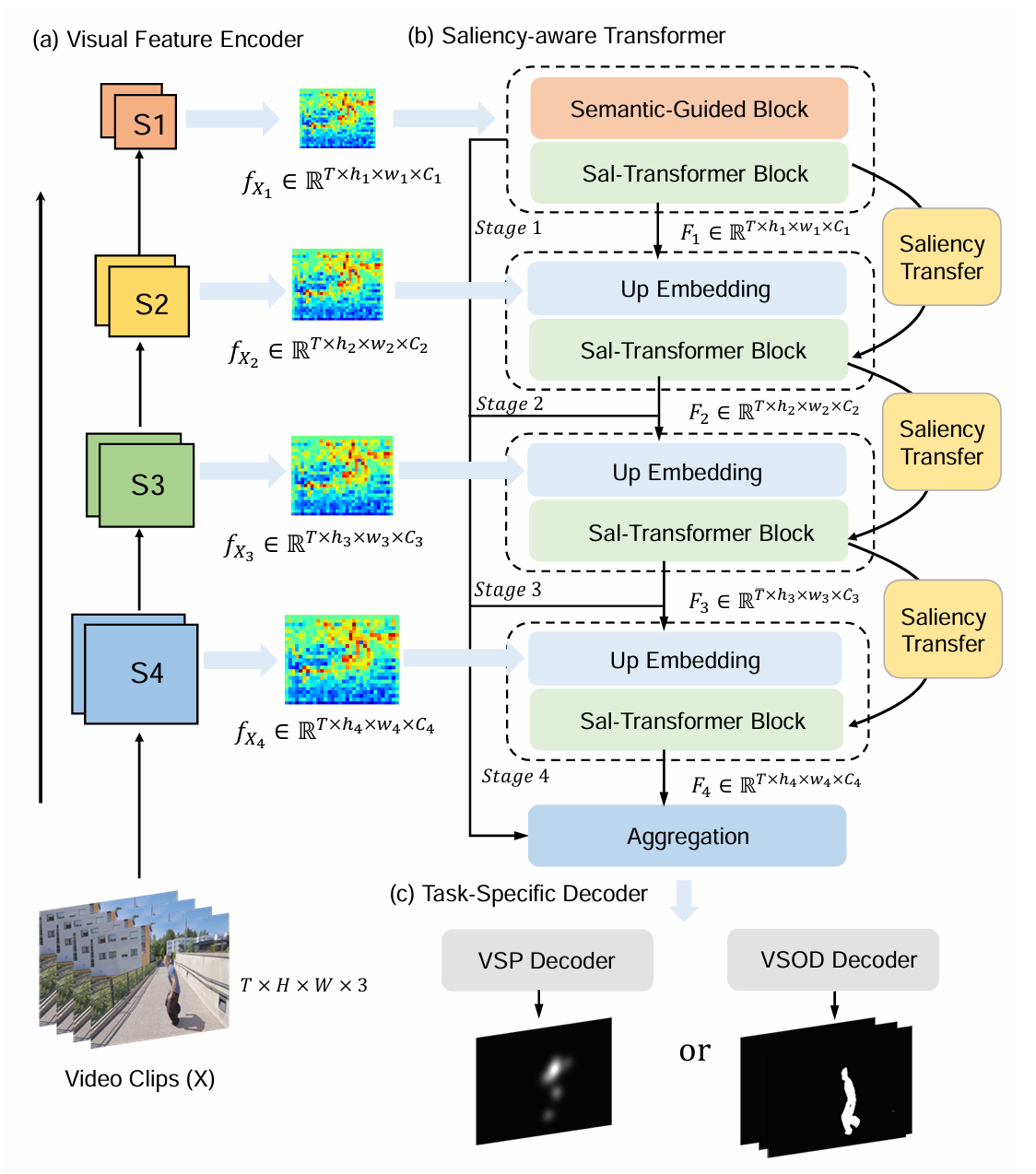
An overview of the proposed UniST. The visual feature encoder learns frame-wise visual representations from the video clips.
The multi-scale visual features are then used as inputs to the saliency-aware transformer for global spatio-temporal modeling, generating refined and scaled-up spatio-temporal features for final prediction.
The saliency transfer mechanism gathers the attention scores in each transformer stage and uses them to improve saliency prediction as well as salient object detection.