|
Junwen Xiong
Hi, I am Junwen Xiong (熊俊文),
a second-year Ph.D. student in the
Department of Computer Science
at Northwestern Polytechnical
University, advised by Prof.
Peng Zhang.
I'm broadly interested in multimodal
learning (images, audio, video, etc.).
My recent research lies in audio-visual
speech separation, sound source
localization.
Email
|
Google
Scholar |
Github
|
|
- [Fer. 2025] One paper UniST is accepted by
TCSVT'25.
- [Mar. 2024] One paper DiffSal is accepted to
CVPR'24.
- [Feb. 2023] One paper about audio-visual
saliency prediction is accepted to
CVPR'23.
- [Aug. 2022] One paper about multi-modal
correlation learning is accepted by
TMM'22.
|
|
Towards Unifying Saliency Transformer for Video Saliency Prediction and Detection
Junwen Xiong,
Chuanyue Li; Tianyu Liu; Peng Zhang; Yue Huo; Wei Huang; Yufei Zha
TCSVT, 2025
[paper]
[webpage]
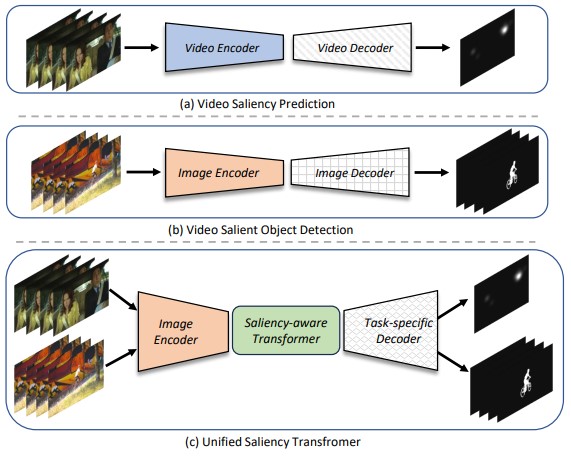
Is it possible to build a unified
saliency model generalized to video
saliency prediction and video salient
object detection tasks? Sure!
|
|
|
DiffSal: Joint Audio and Video Learning for Diffusion Saliency Prediction
Junwen Xiong,
Peng Zhang, Tao You, Chuanyue Li, Wei Huang,
Yufei Zha
CVPR, 2024
[paper]
[webpage]
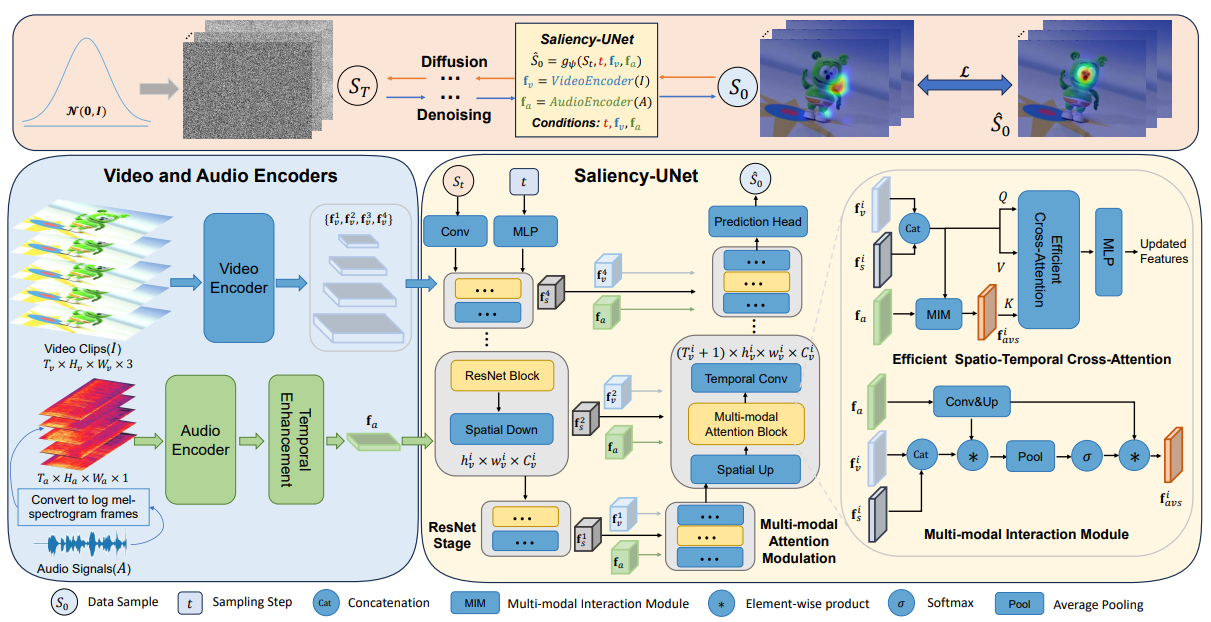
Generalized audio-visual saliency prediction framework
|
|
|
CASP-Net: Rethinking Video Saliency
Prediction from an Audio-Visual
Consistency Perceptual Perspective
Junwen Xiong,
Ganglai Wang, Peng Zhang, Wei Huang,
Yufei Zha, Guangtao Zhai
CVPR, 2023
[paper]
[webpage]
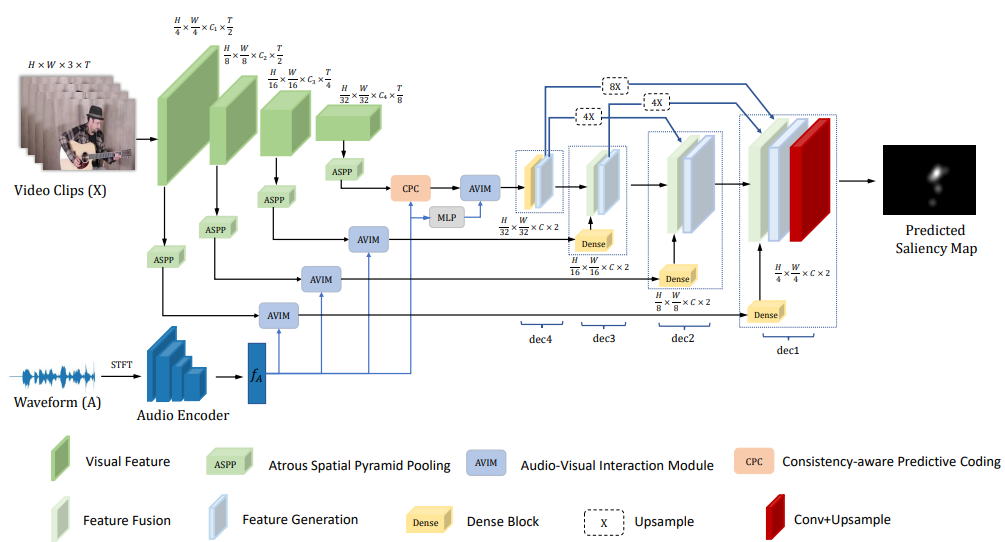
Audio-visual consistency perception
matters
|
|
|
Look&Listen: Multi-Modal Correlation
Learning for Active Speaker Detection
and Speech Enhancement
Junwen Xiong,
Yu Zhou, Peng Zhang, Lei Xie, Wei Huang,
Yufei Zha
TMM, 2022
[paper]
[webpage]
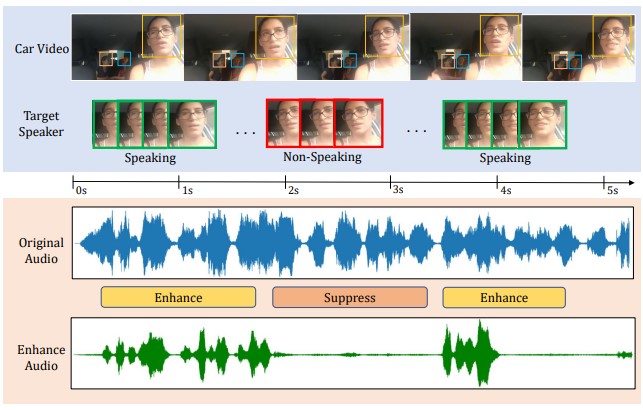
Unified correlation learning framework to
solve two audio-visual tasks
|
|
|
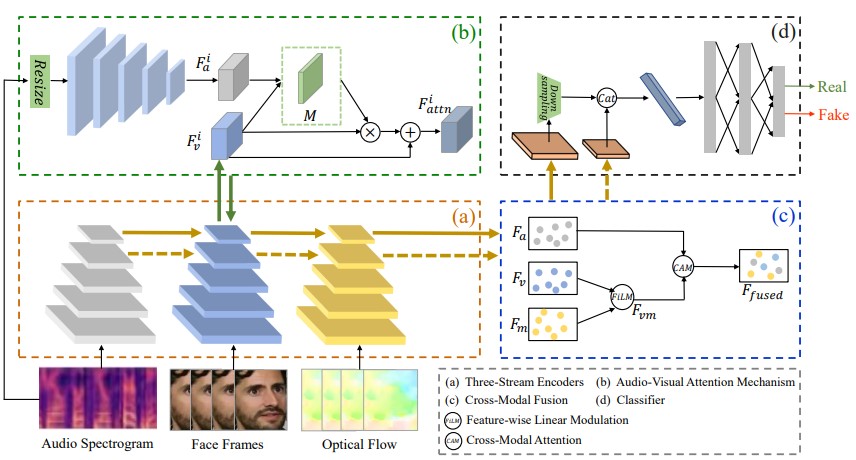
FTFDNet: Learning to Detect Talking
Face Video Manipulation with
Tri-Modality Interaction
Ganglai Wang, Peng Zhang, Junwen
Xiong, Feihan Yang, Wei
Huang, Yufei Zha
[paper]
Incorporating three modalities to detect
talking face video manipulation
|
|
|
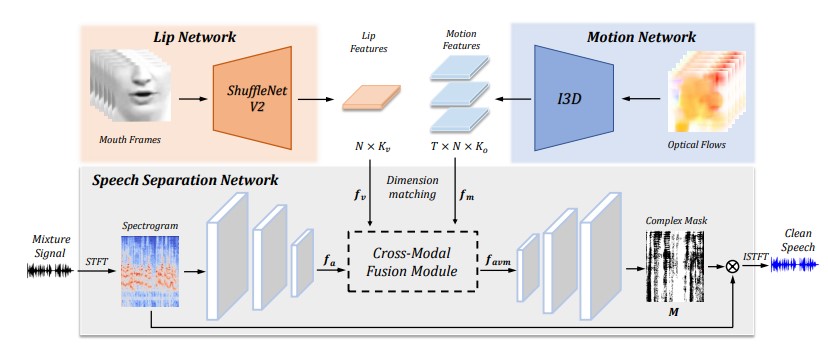
Audio-visual speech separation based
on joint feature representation with
cross-modal attention
Junwen Xiong,
Peng Zhang, Lei Xie, Wei Huang, Yufei
Zha, Yanning Zhang
arXiv preprint, 2022
[paper]
Novel fusion methods for audio, video and
optical flow modalities
|
|
Journal Reviewing: Image and Vision Computing, TCSVT.
Conference Reviewing: ECCV 2024, ICLR 2025, CVPR 2025, ICCV 2025, ICML 2025, NeurlPS 2025.
|
|